注:本文斜体部分均为引用《极客时间-茹炳胜-测试52讲》的“如何设计一个“好的”测试用例?”一章节。整理本文的重要目的是加深自己对测试的理解,并在工作中实践。
设计测试用例是测试工程师最基础最核心的能力。业界往往会浅显地误解,测试工程师的升级就是从功能测试到掌握各种工具的自动化测试,而忽视了测试用例设计能力。其实,不管GUI自动化还是API自动化,无非是在测试用例的基础上,辅之以代码工具来执行用例而已。在谈论GUI自动化或API自动化前,先要把测试用例写好,写好测试用例也是评价一个测试工程师是初级水平和中高级水平的必备条件之一。
那么,回到测试用例上,什么样的测试用例才可以被称之为“优秀的测试用例”呢?“好的”测试用例一定是一个完备的集合,它能够覆盖所有等价类以及各种边界值。
以“池塘捕鱼”为例,如果把被测试软件看作一个池塘,软件缺陷是池塘中的鱼,建立测试用例集的过程就像是在编织一张捕渔网。“好的”测试用例集就是一张能够覆盖整个池塘的大渔网,只要池塘里有鱼,这个大渔网就一定能把鱼给捞上来。
一个“好的”测试用例,必须具备以下三个特征。
1. 整体完备性: “好的”测试用例一定是一个完备的整体,是有效测试用例组成的集合,能够完全覆盖测试需求。
2. 等价类划分的准确性: 指的是对于每个等价类都能保证只要其中一个输入测试通过,其他输入也一定测试通过。
3. 等价类集合的完备性: 需要保证所有可能的边界值和边界条件都已经正确识别。
做到了以上三点,就可以肯定测试是充分且完备的,即做到了完整的测试需求覆盖。
我们理解了什么是“优秀的测试用例”,那是不是就可以去设计测试用例了呢?,别急,在设计具体的测试用例前,还有一个非常重要的环节——测试需求分析,测试需求分析是衡量初级测试工程师和中高级测试工程师的分水岭。
在具体的用例设计前,首先需要搞清楚每一个业务需求所对应的多个软件功能需求点,然后分析出每个软件功能需求点对应的多个测试需求点,最后再针对每个测试需求点设计测试用例。以下图的登录业务为例,我们理清楚图中的业务需求到软件功能需求、软件功能需求到测试需求,以及测试需求到测试用例的映射关系。
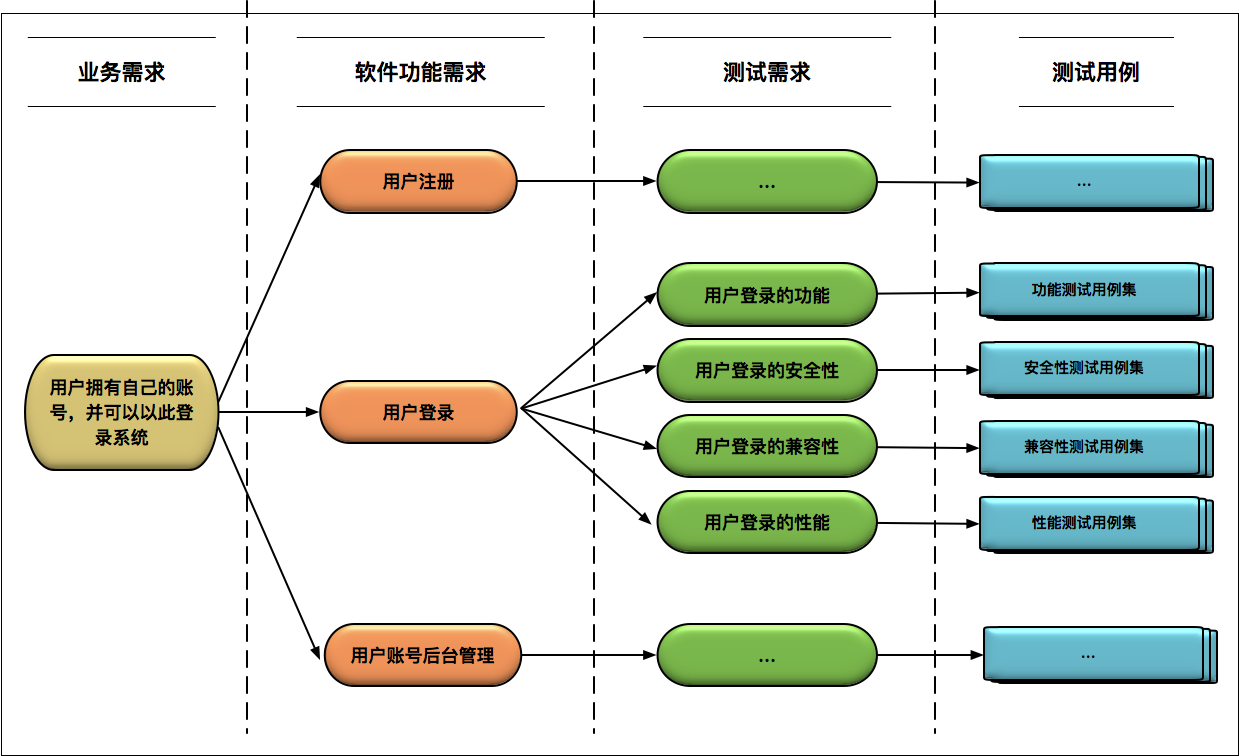
一个登录业务对应着用户注册、用户登录和用户账号后台管理的三个产品功能,而其中的“用户登录”这一产品功能,又对应着“用户登录的功能”、“用户登录的安全性”、“用户登录的兼容性”、“用户登录的性能”、“用户登录的UI界面”等多个测试需求,而“用户登录功能”这一测试需求,又对应着“正确的用户名和正确的密码”、“正确的用户名和错误的密码”、“错误的用户名和正确的密码”、“错误的用户名和错误的密码”以及用户名和密码各自的参数字符类型和字符长度的测试用例,“用户登录的安全性”则对应着“用户登录的时效”、“是否允许多端登录”、“多次输入错误密码是否锁定用户”、“登录频率过高是否提示”、“ip异地登录是否提醒”等安全测试用例;“用户登录的性能”这一测试需求同理,也对应着多个“用户登录的性能测试场景”……
具体到测试用例本身的设计,有两个关键点需要注意。
1. 从软件功能需求出发,全面地、无遗漏地识别出测试需求是至关重要的,这将直接关系到用例的测试覆盖率。 比如,如果你没有识别出用户登录功能的安全性测试需求,那么后续设计的测试用例就完全不会涉及安全性,最终造成重要测试漏洞。
2. 对于识别出的每个测试需求点,需要综合运用等价类划分、边界值分析、错误推断和场景分析法来全面地设计测试用例。 这里需要注意的是,要综合运用这三种方法,并针对每个测试需求点的具体情况,进行灵活选择。
上文提到了测试用例设计的最常用的四个方法(其他方法几乎可以忽略),即等价类划分、边界值分析、错误推断和场景分析法。那这四种方法到底要怎么用呢?
1. 等价类划分。等价类划分要基于MECE原则(Mutually Exclusive Collectively Exhaustive,即相互独立,完全穷尽),去找出所有的有效等价类和无效等价类(大多数人都能找出有效等价类,但却很少人能找全无效等价类)。以“学生信息系统的'考试成绩'输入项”为例。成绩的取值范围是 0~100 之间的整数,考试成绩及格的分数线是 60。
为了测试这个输入项,显然不可能用 0~100 的每一个数去测试。通过需求描述可以知道,输入 0~59 之间的任意整数,以及输入 60~100 之间的任意整数,去验证和揭露输入框的潜在缺陷可以看做是等价的。那么这就可以在 0~59 和 60~100 之间各随机抽取一个整数来进行验证。这样的设计就构成了所谓的“有效等价类”。
此外,也非常重要的是,我们还要找出所有的“无效等价类”。例如,如果输入的成绩是负数,或者是大于 100 的数等都构成了“无效等价类”。
2. 边界值分析。在等价类划分的基础上,我们要找出所有“有效等价类”和“无效等价类”的边界值,从工程实践经验中可以发现,大量的错误发生在输入输出的边界值上,所以需要对边界值进行重点测试,通常选取正好等于、刚刚大于或刚刚小于边界的值作为测试数据。
继续看学生信息系统中“考试成绩”的例子,选取的边界值数据应该包括:-1,0,1,59,60,61,99,100,101。
3. 错误推测方法。错误推测方法是指基于对被测试软件系统设计的理解、过往经验以及个人直觉,推测出软件可能存在的缺陷,从而有针对性地设计测试用例的方法。这个方法强调的是对被测试软件的需求理解以及设计实现的细节把握,当然还有个人的能力。
错误推测法和目前非常流行的“探索式测试方法”的基本思想和理念是不谋而合的,这类方法在目前的敏捷开发模式下的投入产出比很高,因此被广泛应用。但是,这个方法的缺点也显而易见,那就是难以系统化,并且过度依赖个人能力。
比如,Web 界面的 GUI 功能测试,需要考虑浏览器在有缓存和没有缓存下的表现;“登陆模式”和“游客模式”的接口鉴权是否有差异;多次点击或并发调用接口,是否会导致提交多条重复的数据;Web Service 的 API 测试,需要考虑被测 API 所依赖的第三方 API 出错下的处理逻辑…
在具体工作实践中,为了降低对个人能力的依赖,通常会建立常见缺陷知识库(一个推荐的做法是建立共享协作的wiki页),在测试设计的过程中,会使用缺陷知识库作为检查点列表(checklist),去帮助优化补充测试用例的设计。让测试工程师完成测试用例的最初设计后对应这个 wiki 页面先做一轮自检,如果在后续测试中发现了新的点,就会继续完善这个 知识库。例如:https://shimo.im/docs/QKjkwjD9WJGv6CCh。
最后,分享两个用例设计的两个经验。
1. 只有深入理解被测试软件的架构,你才能设计出“有的放矢”的测试用例集,去发现系统边界以及系统集成上的潜在缺陷。
作为测试工程师,切忌不能把整个被测系统看作一个大黑盒,你必须对内部的架构有清楚的认识,比如数据库连接方式、数据库的读写分离、消息中间件 Kafka 的配置、缓存系统的层级分布、第三方系统的集成等等。
2. 必须深入理解被测软件的设计与实现细节,深入理解软件内部的处理逻辑。
单单根据测试需求点设计的用例,只能覆盖“表面”的一层,往往会覆盖不到内部的处理流程、分支处理,而没有覆盖到的部分就很可能出现缺陷遗漏。在具体实践中,你可以通过代码覆盖率指标找出可能的测试遗漏点。
同时,切忌不要以开发代码的实现为依据设计测试用例。因为开发代码实现的错误会导致测试用例也出错,所以你应该根据原始需求设计测试用例。
提交评论
您尚未登录,登录后方可评论~ 登录 or 注册